清晨,我如往常一样,起床后查阅自己的邮箱。由于论文在5月份的时候就完成了所有的收尾工作,导师非常愉快给了我暑期三个月的带薪休假,让我回家看看父母。回国之后,凡是工作上的事情都得借助梯子的帮助。挂上梯子,打开学校邮箱,映入眼帘的便是醒目的 “HotCRP” 几个字母。这几个字母太熟悉不过了,这是软工顶会之一 ASE (38th IEEE/ACM International Conference on Automated Software Engineering) 的论文审稿结果通知。虽然自己对这次的论文很有信心,但是面对着这装着审阅结果的邮件,还是不禁有些紧张与忐忑,无法下决心点开邮件一看究竟。
好在,导师的邮件也发了过来。看到邮件的第一个单词 “Congratulation”,我终于松了一大口气,开始仔细阅读导师邮件的内容。
1
2
3
4
5
6
Congratulations on the ASE paper acceptance!
Two accepts and 1 weak accept is a fantastic set of reviews,
very well done!
I am proud of you and the paper you put together.
随着信件的展开,内心被喜悦与肯定填满。允许我小小骄傲一下哈哈,收获了这样的结果给了我莫大的激励,也算是这两年漂泊坎坷科研路落定。其实,我与我现在的导师 Lukasz Ziarek 刚共事了半年。之前带了我两年的华人导师跳槽到了南加大,她临走前承诺带我一起转过去。我自以为足够幸运,能够沾着导师的福气,去到我梦想中的学校。但事与愿违,我没能过去,也明白了所谓成功,都要靠自己的实力去争取。后来,很幸运的是,我遇到了新的导师 Lukasz。
Lukasz 是副教授,他是一个年轻充满活力但严谨治学的、也是系里公认的特别友善的老师。Lukasz总是对科研问题和教导学生有着饱满的热情。每周一次在他办公室的单人会议,因为他对我研究的方向并不熟悉,便让我在白板上写写画画,为他讲解专业知识,汇报我一周的科研进展,他当一个听众。这时我俨然成为了一位老师,尽管我的知识水平有限,但他在下面仍仔细地听完我的陈述,赞许我的成果,全部讲完后与我一同平等地探讨一些尚未解决的问题。
罗素认为有趣的工作有两个属性,一个是充满技巧性,另一个是富有创造性。显然,科研工作很好地占据了这两个属性。而除此之外,我认为还有一个不可忽视的因素,就是能够与一个赏识你的人分享工作中的趣味。Lukasz 便是这个人,是我科研中的伙伴,愿意倾听我的快乐和烦恼;是我求学路上的前辈,帮我解惑答疑。和他的例会是我每周最期待的事情,只有在那时,我才有舞台分享我在科研过程中发现新事物的喜悦。
在他的指导下,这篇论文从最初的想法到被会议接收,加上两个月的审稿期,前前后后只花了六个月时间。从1月中旬,我开始细化想法并从零开始写代码搭建实验环境,到3月初便完成了大部分实验,然后花了将近1个月时间完成论文初稿和剩下的实验,并将论文中的工作整合成一个浏览器插件在平台上公开。在论文投稿截止前一个半月,我便完成了所有的基础工作,留下了充足的时间对文章进行打磨。每周 Lukasz 都会为我抽出来两个小时,一起坐在他的办公室中对论文中的每一处细节字斟句酌,后来还将成稿发给我的博士朋友们,收集大家的反馈意见。最后一直到改无可改,在5月18日截止期前的几天早早地递交了论文,然后进入漫长的审稿期。身边许多华人老板的实验室都有在投稿截止最后一个晚上熬夜赶稿的传统,但我并不感冒这种临阵磨枪式的努力。《孙子兵法》曾言,善战者无赫赫之功,胜兵先胜而后求战,败兵先战而后求胜。也就是说,胜利之师是先具备必胜的条件然后再交战,而失败之军总是先同敌人交战,然后期求从苦战中侥幸取胜。与其一轮一轮地改稿重投,不如做好万全准备一次拿下胜利。
2个月后,也就是今天,我终于收到了审稿回复——两个 Accepts 和一个 Weak Accept(其实应该是三个 Accepts,其中一个审稿人看漏了文中的关键信息,给出了 Weak Accept)。根据审稿意见,全文没有逻辑上的漏洞,只需要文字编排上的小修小补。能够得到审稿人的认可,无比欢欣。这也算是拿到了科研的入场券,可以准许我在这条路上继续前进,继续与他人分享探索过程中的体会。
以下是对这篇论文内容的概述。
文章介绍了一种的新的检测 Web 第三方库的方法—— pTree 比对。pTree 意为 Property Tree,是由我们提出的用于 Web 软件分析的数据结构,它以树的形式刻画了软件运行时所有可供调用的变量信息。我们发现第三方库加载到网页上之后,其原生的 pTree 会被整体加载进全局变量空间。因此我们可以通过将网页和众多第三方库的 pTree 进行比对,来确定网页加载的库。
传统的库检测工具,例如 LDC(Library Detector for Chrome)和 Wappalyzer,都是通过检测单个变量信息来推断库的存在性。这种检测方法原理简单容易实现,但是准确率不高,而且需要熟悉库的专业人员判断最能代表库的变量。现在随着 Web 库的数量呈指数式增长,库的版本迭代也越来越快,这种靠人工收集检测特征的传统方法越来越不能适应当下 Web 快速发展的需要。在此,我们推出了新的检测工具 PTdetector,能够自动提取库的 pTree 作为检测特征,通过网页运行时的 pTree 比对来实现对已加载库的精准检测。

上图展示 PTdetector 根据为 Web 库计算其 pTree 的流程。主要分为三个部分:
- 依赖去除:去除依赖库对 pTree 产生的影响;
- 计算权重:我们提出了一个启发式的算法对 pTree 的每个节点的权重进行赋值。在检测中起到重要作用的节点能得到更高的权重;
- 倒排索引:生成索引文件,供运行时检测使用。
PTdetector 的工作流程详情参见论文的第三章。
由于 pTree 的每个节点都赋予了权重,因此运行时匹配时能够计算出一个相似度分数,取值在 0 - 100 之间,100 则表示全部节点都完全匹配。我们设定一个阈值 t,如果相似度分数大于 t,则我们判断该库存在,否则不存在。在文章的实验部分,我们在 200 个用户流量最多的大型网站上对 PTdetector 和传统工具中性能最强的 LDC 进行了比较。下图展示了 PTdetector 检测结果的 accuracy,precision 和 recall。
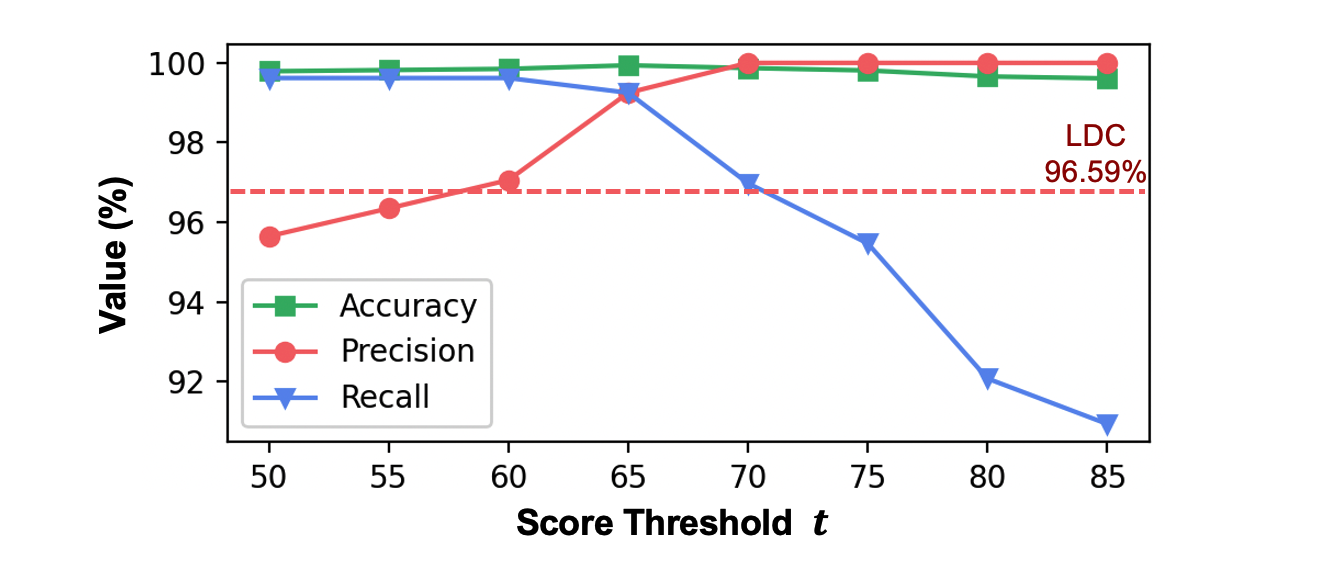
从图中可以看到,当阈值 t 取为 68% 时,PTdetector 的 precision 达到了 100%,超过 LDC 的 96.59%。同时 PTdetector 的 recall 为 98.11%,远超过 LDC 的 83.33%(超出图表范围未在图中标出)。
PTdetector 的前端检测部分我们做成了 Chrome 插件,发布在了 Github 上。由于工具还有很多优化之处,所以暂未上架 Chrome 应用商城。我们后续会做更多工作,完善 PTdetector 的检测能力。此外,论文中的所有数据和图表也都公布在了 Github 上,并以 Python Jupyter Notebook 的形式展现出来,方便读者了解图表生成的全过程。